Large Language Models - Concepts, Use cases and Applications

What is a Large Language Model (LLM)?
A Large Language Model (LLM) is a type of artificial intelligence model designed to process and generate human-like text. Built on advanced deep learning architectures, typically transformers, LLMs are trained on vast datasets of text to understand language patterns, context, and meaning. They are used for a wide range of tasks, including text generation, translation, summarization, question-answering, and conversational AI.
How Does an LLM Work?
LLMs operate by predicting the next word in a sequence, given a context of preceding words. This is achieved through a two-phase process:
Training Phase:
LLMs are trained on large-scale corpora, such as books, articles, websites, and codebases.
The training involves maximizing the likelihood of correct word predictions using self-supervised learning, where the model learns from the structure of text itself without requiring explicit labels.
Training uses GPUs or TPUs to handle computations involving billions of parameters over many iterations.
Inference Phase:
After training, LLMs can generate responses or perform tasks based on input queries (prompts).
In this phase, the model leverages the patterns and relationships learned during training to produce coherent and contextually relevant text.

Figure 1 - Basic Flow of LLMs
Key Concepts in LLMs
Transformers:
LLMs are typically built on the Transformer architecture, introduced in 2017. Transformers use self-attention mechanisms to focus on relevant parts of input data, allowing them to process long sequences of text efficiently.
Self-Attention enables the model to weigh the importance of words relative to others in a sentence, capturing context effectively.
Tokens and Tokenization:
LLMs process text as discrete units called tokens, which may represent words, subwords, or even characters.
Tokenization is the process of splitting text into these units, enabling models to handle diverse languages and structures.
Parameters:
Parameters are the model’s internal values learned during training. They determine how the model weighs different aspects of the input.
LLMs like GPT-4 may have hundreds of billions of parameters, allowing them to store and apply complex language patterns.
Pretraining and Fine-Tuning:
Pretraining: The model is initially trained on general-purpose text datasets to learn foundational language skills.
Fine-tuning: The pretrained model is further trained on task-specific data to specialize in particular applications (e.g., customer support, medical QA).
Embedding:
Text is converted into numerical representations called embeddings that capture semantic meaning. These embeddings enable the model to process and compare text efficiently.
Loss Function:
The training process uses a loss function, typically cross-entropy loss, to measure the difference between predicted and actual tokens. The model minimizes this loss to improve accuracy.
Reinforcement Learning with Human Feedback (RLHF):
For applications like conversational AI, models are fine-tuned with human feedback to align their outputs with user expectations and ethical considerations.
Applications and Challenges
Applications:
Text completion (e.g., autocomplete in IDEs)
Chatbots and virtual assistants (e.g., ChatGPT)
Machine translation
Sentiment analysis and text classification
Document summarization
Challenges:
Scalability: Training LLMs requires significant computational resources and energy.
Bias and Fairness: Models can inadvertently learn and reproduce biases present in their training data.
Interpretability: Understanding why LLMs make certain predictions remains difficult.
Data Privacy: Using sensitive or proprietary text data raises privacy concerns.
Transformer Architecture in LLMs
The transformer architecture is the backbone of most modern Large Language Models (LLMs). It was introduced in the seminal paper "Attention is All You Need" (Vaswani et al., 2017). Transformers revolutionized natural language processing (NLP) by enabling models to process entire input sequences simultaneously, as opposed to earlier sequential approaches like Recurrent Neural Networks (RNNs).

Figure 2 - Transformation Architecture Model
Key Components of Transformer Architecture
Self-Attention Mechanism:
Self-attention allows the model to weigh the importance of each token in the input sequence relative to others, enabling context-aware understanding.
It computes attention scores to capture relationships between words, regardless of their position in the text.
Multi-Head Attention:
Instead of computing attention once, multi-head attention computes it multiple times with different learned projections, allowing the model to capture diverse relationships.
Positional Encoding:
Transformers process input sequences in parallel, so positional encodings are added to tokens to represent their order in the sequence.
Feed-Forward Layers:
Fully connected neural layers applied independently to each token position, enabling complex transformations of representations.
Residual Connections and Layer Normalization:
Residual connections improve gradient flow during training, while layer normalization ensures stable training dynamics.
Encoder-Decoder Structure:
The transformer architecture originally consisted of:
Encoder: Processes input data into a context-aware representation.
Decoder: Generates output sequences based on encoder outputs.
In LLMs like GPT, only the decoder is used for autoregressive tasks, whereas models like BERT use only the encoder for bidirectional tasks.
Advantages of Transformers
Parallelism:
Unlike RNNs, which process tokens sequentially, transformers process entire sequences simultaneously, making them faster to train.
Contextual Understanding:
Self-attention allows models to understand long-range dependencies between words in a sequence.
Scalability:
Transformers scale well to very large datasets and model sizes, which is essential for LLMs like GPT-4, PaLM, and LLaMA.
Versatility:
The architecture can be applied to various domains beyond NLP, including computer vision (Vision Transformers) and audio processing.
Other Architectures Used in NLP and LLMs
Although transformers dominate the landscape of LLMs, earlier architectures and some modern innovations also play a role:
1. Recurrent Neural Networks (RNNs)
Sequential models that process one token at a time.
Include variations like LSTMs (Long Short-Term Memory) and GRUs (Gated Recurrent Units).
Limitations: Struggle with long-range dependencies and lack parallelism.
2. Convolutional Neural Networks (CNNs) for NLP
Originally used in computer vision, CNNs have been adapted for NLP tasks by applying convolutions over sequences of words or characters.
Faster than RNNs but less capable of capturing long-term dependencies compared to transformers.
3. Attention-Based Models (Pre-Transformer)
Models like seq2seq with attention introduced attention mechanisms to improve performance on tasks like machine translation.
The transformer architecture generalized these concepts to all layers.
4. Hybrid Architectures
Combine RNNs or CNNs with transformers to leverage the strengths of each.
Example: Transformer-XL, which extends the transformer with recurrence for better handling of long sequences.
5. Sparse Transformers
Introduced to handle long sequences more efficiently by computing attention only for a subset of tokens.
Example: Longformer for documents and Reformer for memory-efficient computation.
6. Retrieval-Augmented Models
Combine transformers with external retrieval systems (e.g., Retrieval-Augmented Generation or RAG).
Use retrieval to enhance the generative model’s outputs with specific knowledge.
7. Sequence-to-Sequence Models (Seq2Seq)
Used in tasks like machine translation.
The transformer itself was a significant improvement on seq2seq models with attention.
8. Diffusion Models (Emerging)
While primarily used in image generation (e.g., DALL-E), diffusion models are being explored for generative tasks in NLP.
9. Graph Neural Networks (GNNs)
Focus on relationships and structures in data, such as knowledge graphs.
Typically used alongside transformers to improve context understanding for tasks like recommendation systems.
Comparison of Architectures

Sparse Transformers
Excellent at context understanding.
Efficiently handle long sequences with minimal computational cost.
Low computational cost.
Transformers
Excel at understanding long-range dependencies.
Highly effective but computationally expensive.
High computational cost.
Recurrent Neural Networks (RNNs)
Cost-effective for sequential data.
Struggle with capturing long-range dependencies.
Limited context understanding.
Convolutional Neural Networks (CNNs)
Computationally intensive.
Limited ability to understand global context.
Limited context understanding.
Transformers vs. Other Architectures
Transformers dominate modern NLP because of their unparalleled ability to capture global context, scalability, and flexibility.
Other architectures, like RNNs and CNNs, are largely relegated to specific tasks or integrated as components in hybrid systems.
Transformers have proven versatile enough to power not only LLMs like GPT-4, BERT, and PaLM but also cutting-edge applications in other domains, marking a paradigm shift in machine learning architecture.
RAG (Retrieval- Augmented Generation)
RAG (Retrieval-Augmented Generation) is a technique in Natural Language Processing (NLP) that combines a retrieval system with a generation model (usually a Large Language Model, or LLM) to enhance the quality and relevance of responses. It is particularly useful in scenarios where the LLM might lack up-to-date or domain-specific knowledge, or when the model's training data does not cover specific user queries.
How RAG Works
RAG operates in two main stages:
Retrieval Phase:
Relevant information is fetched from an external knowledge base, database, or document repository using a retrieval system.
Retrieval methods typically use tools like:
Vector search: Finds semantically similar documents using embeddings (e.g., with tools like FAISS or Pinecone).
BM25: A traditional keyword-based retrieval algorithm.
Generation Phase:
The retrieved documents are fed into an LLM (e.g., GPT, BERT-based models) along with the user query.
The model generates a response by combining its generative capabilities with the context provided by the retrieved documents.
Key Components of RAG
Retrieval System:
Finds and ranks relevant documents or data from an external source.
May involve semantic search or keyword-based search.
Large Language Model:
Generates coherent and contextually accurate responses using retrieved data and its own linguistic understanding.
Knowledge Base:
The external source of information, such as a database, a set of documents, or an enterprise knowledge repository.
Why Use RAG?
Knowledge Updating:
LLMs like GPT-4 are trained on static datasets and may lack recent or specialized knowledge. RAG enables them to access up-to-date information.
Scalability:
Instead of embedding vast amounts of domain-specific data into the LLM, RAG dynamically retrieves information, reducing computational and storage costs.
Domain Expertise:
RAG allows the model to incorporate specific, fine-grained knowledge that may not be present in its training data.
Reduced Hallucinations:
By grounding responses in retrieved factual documents, RAG minimizes the risk of the model generating incorrect or fabricated information.
Use Cases of RAG in LLMs
Customer Support
Answers complex queries by retrieving company policies or FAQs.
Example: Chatbots integrated with enterprise knowledge bases.
Legal Document Analysis
Provides answers or summaries from legal text corpora.
Example: AI-powered legal assistants (e.g., contract analysis tools).
Healthcare Applications
Offers medical advice by referencing clinical guidelines or literature.
Example: AI assistants for doctors (e.g., retrieving studies or drug info).
Educational Tools
Generates answers or content using textbooks or scientific papers.
Example: AI tutors referencing syllabi or research publications.
E-Commerce Search
Recommends products and resolves customer issues by accessing catalogs or manuals.
Example: Intelligent search features on platforms like Amazon.
Enterprise Knowledge Management
Helps employees retrieve relevant documents from internal databases.
Example: Microsoft Copilot, Salesforce Einstein GPT.
Research Assistance
Fetches relevant academic papers and scientific findings for researchers.
Example: Semantic Scholar, tools integrated with ArXiv.

Advantages of RAG
Efficiency:
Dynamically retrieves specific information instead of relying on the LLM's memory alone.
Flexibility:
Works with a wide variety of external data sources, including structured and unstructured data.
Accuracy:
Grounded in factual, retrieved data, improving the reliability of responses.
Cost-Effective:
Eliminates the need to fine-tune LLMs on every domain-specific dataset.
Challenges in RAG
Retrieval Quality:
The effectiveness of RAG depends heavily on the retrieval system's ability to fetch relevant documents.
Latency:
The two-step process (retrieval and generation) can increase response times.
Data Management:
Ensuring the knowledge base is accurate, up-to-date, and free of sensitive information is critical.
Context Handling:
Integrating retrieved information seamlessly into the LLM's response while maintaining coherence can be complex.
Popular RAG Implementations
OpenAI GPT with Retrieval:
Integration of tools like Pinecone or FAISS to retrieve context before feeding queries to GPT models.
LangChain Framework:
A Python-based framework for building RAG pipelines by combining LLMs with external data retrieval.
Hybrid Search Systems:
Combining traditional search techniques (BM25) with embedding-based methods for improved retrieval.
Google Bard:
Uses retrieval-augmented techniques to deliver up-to-date and relevant information to user queries.
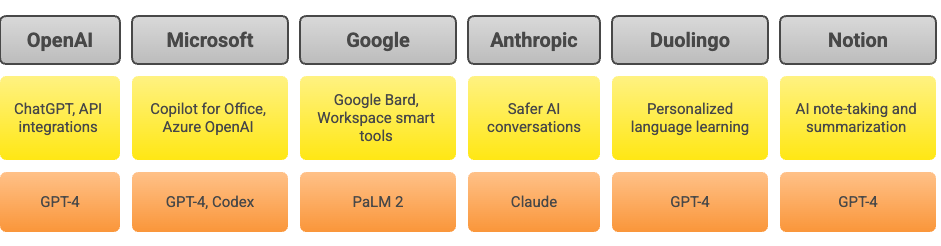
Applications of Various Large Language Models (LLMs)
Large Language Models (LLMs) have revolutionized natural language processing (NLP) and artificial intelligence (AI), finding applications across diverse industries. For chatbots and conversational AI, models like GPT-4, Claude, and ChatGLM power customer support and virtual assistants. In text generation, GPT-4, GPT-3.5, PaLM, and Falcon are used for creative writing and marketing content. Summarization tasks such as condensing legal briefs and meeting notes rely on GPT-4, BERT, T5, and Flan-T5. For translation, models like PaLM 2, Bloom, and ChatGLM handle multilingual support and document translation.
In sentiment analysis, Cohere, BERT, and Bloom help companies process social media and customer feedback. Question answering systems like GPT-4, Claude, and Falcon are used in chatbots, FAQs, and knowledge retrieval. Code assistance is supported by Codex, GPT-4, and CodeT5, helping developers with IDE integration and coding suggestions. For personalized recommendations like product suggestions or playlist generation, companies use GPT-4, Claude, and Bloom.
Document analysis tasks such as contract review and resume screening are powered by Claude, Ernie Bot, and LLaMA. In medical applications, GPT-4, MedPaLM, and Bloom assist with diagnosis suggestions and patient Q&A. In education and training, GPT-4, Duolingo AI, and PaLM create tutoring experiences and educational materials. Search engine enhancements, including semantic and voice search, are driven by GPT-4, Claude, and Ernie Bot.
In gaming, GPT-4 and DALL-E enable dynamic storytelling and quest creation. For legal applications, GPT-4, LLaMA, and Cohere support contract drafting and legal research. In news and journalism, GPT-4, Flan-T5, and Bloom help automate article writing and news summarization. Data analysis and insights such as market trend analysis and financial summaries are powered by GPT-4, Claude, and Falcon.
Multimodal applications — combining text with images or video — use GPT-4, CLIP, and PaLM 2 for tasks like image captioning and video summarization. Content moderation, ensuring social media compliance, is supported by GPT-4, Cohere, and Ernie Bot. In social media analysis, GPT-4, Bloom, and BERT detect trends and measure campaign performance.
For cybersecurity, Falcon, GPT-4, and Granite are used for threat detection and log analysis. In recruitment and HR, GPT-4, Claude, and BERT streamline resume screening and job description generation. Creative design projects, like ad campaigns and storyboarding, are assisted by DALL-E and GPT-4. In financial services, GPT-4, Claude, and Falcon help with fraud detection and risk assessment.
Voice assistance for smart homes and vehicles is powered by GPT-4, ChatGPT, and PaLM. Finally, environmental monitoring tasks, such as weather prediction and environmental impact assessment, are supported by GPT-4, Cohere, and Falcon.